For the 2PC and 1PC commit protocols, fill up the following table, where ERT refers to ``Earliest Release Time'' w.r.t. the protocol's communication and logging action sequence (e.g. Immediately after receiving StartWork message).
| Commit | E R T | E R T |
| Protocol | Read Locks | Write Locks |
| 1PC | ||
| 2PC |
Assume that
- A Strict-2PL-like protocol is used to ensure serializability and no cascading aborts.
- The table entries are for the cohorts of committed transactions. (4 marks)
With these definitions, an item-set ![]() is said to be ``complete''
if and only if
is said to be ``complete''
if and only if
![]() . Your project partner claims that if
he were ``magically'' given the identities and supports of only
the complete frequent item-sets in the item-set lattice, then he would
be able to establish the identities and supports of all frequent
item-sets without having to scan the database, and thereby
discover the association-rules trivially.
. Your project partner claims that if
he were ``magically'' given the identities and supports of only
the complete frequent item-sets in the item-set lattice, then he would
be able to establish the identities and supports of all frequent
item-sets without having to scan the database, and thereby
discover the association-rules trivially.
- Do you believe the claim w.r.t. establishing all frequent item-set
identities? Explain.
(5 marks)
- For the frequent itemsets that are identifiable (if any), do you believe the claim w.r.t. establishing their supports? If yes, describe an algorithm for computing the supports. If no, explain why and show a sample scenario of the failure. (5 marks)

- The hashing function uses B bits of the hash-value, progressively
going from left-to-right in this bit segment. Do you think
it is equally acceptable to go from right-to-left in the bit
segment? (2 marks)
- Recall that in the Linear Hashing paper, we had discussed the
high-quality randomizing hash function: [(A k) mod w] where
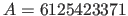 ,
, 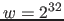 , and
, and 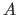 is prime wrt
is prime wrt 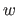 .
Your project partner suggests that after incorporating a ``mod
.
Your project partner suggests that after incorporating a ``mod 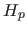 ''
factor, this function can be used during the initial clustering phase in
memory-resident joins to improve the distribution of data values across
the clusters. Explain how you would respond to this suggestion.
(2 marks)
''
factor, this function can be used during the initial clustering phase in
memory-resident joins to improve the distribution of data values across
the clusters. Explain how you would respond to this suggestion.
(2 marks)
- For both these options, calculate the number of L1 and L2 cache misses during a search and compute the aggregate cost of cache misses in terms of cpu cycles. Show which one is more efficient. (3 marks)
- How do these options compare in terms of the node split cost? (3 marks)
Do you agree with the above claim? If yes, validate it by providing your most efficient join algorithm that exploits the existing partition information to implement the binary join operation for a predicate of the form A.x = B.y. If no, explain why. (5 marks)