No changes would have to be made since the DBMS provides independence between the application layer and the physical layer.
The relations are identical since they have the same attributes and contain identical information. (Relations are a set of unordered columns and rows.)
SELECT cname
FROM COMPANY
WHERE (type = "private") AND cname NOT IN
( ( SELECT p.cname
FROM PROJECT p
GROUP BY p.cname
HAVING ( ( COUNT (DISTINCT pstate) > 1) AND
( COUNT (DISTINCT pstate) <> COUNT (pname) ) ) )
UNION
( SELECT h.cname
FROM HIRE h, PROJECT p, WORKER w
WHERE (h.cname = p.cname) AND
(h.pname = p.pname) AND
(h.EBno = w.EBno) AND
( ( p.pstate <> w.wstate ) OR
( ( SELECT COUNT (*)
FROM EXPERIENCE e
WHERE (w.EBno = e.EBno)) <> 3 ) ) ) )
ORDER BY cname ASC
- The first step is to check whether the decomposition is lossless-join.
This can be done using the Table algorithm of Ullman (Algorithm 7.2).
Applying this algorithm results in the row corresponding to relation
scheme DGRS becoming ``all a'' indicating a lossless join.
- The second step is to evaluate the BCNF claim.
The two-attribute relations (CP, RT, AL) are in BCNF by definition (Lemma 7.7
in Ullman). For CDR, a candidate key is DR. Therefore, the only
possible violations of BCNF in
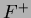 are
are
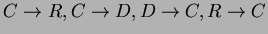 . By taking attribute closures of
LHS, we can show that none of these f.d. are in . Therefore,
CDR is in BCNF. For LSX, a candidate key is S. Therefore, only possible
violations of BCNF in are
. By taking attribute closures of
LHS, we can show that none of these f.d. are in . Therefore,
CDR is in BCNF. For LSX, a candidate key is S. Therefore, only possible
violations of BCNF in are
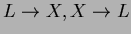 . Again,
we can show by taking attribute closures of LHS that neither is in .
Finally, for DGRS, a candidate key is GR. The violations possible are
. Again,
we can show by taking attribute closures of LHS that neither is in .
Finally, for DGRS, a candidate key is GR. The violations possible are
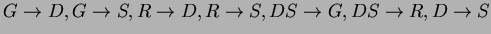 . None of these are in .
. None of these are in .
Therefore, the BCNF claim is correct.
- Dependency preservation claim: Consider the f.d.
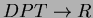 in
F and apply Algorithm 7.3 in Ullman. We find that R does not appear in
the result of this procedure. Therefore, the decomposition is not
dependency preserving. Other dependencies which are not preserved
are
in
F and apply Algorithm 7.3 in Ullman. We find that R does not appear in
the result of this procedure. Therefore, the decomposition is not
dependency preserving. Other dependencies which are not preserved
are
 and
and
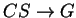 .
.
Test C, the BCNF definition test is guaranteed to decide the decomposition identity since the 3NF scheme will fail this test definitely. The outcome of Test B will succeed for both the BCNF and the 3NF decompositions. The outcome of Test A may or may not succeed for both 3NF and BCNF. Test D will always succeed for both decompositions since BCNF is a special subset of 3NF.
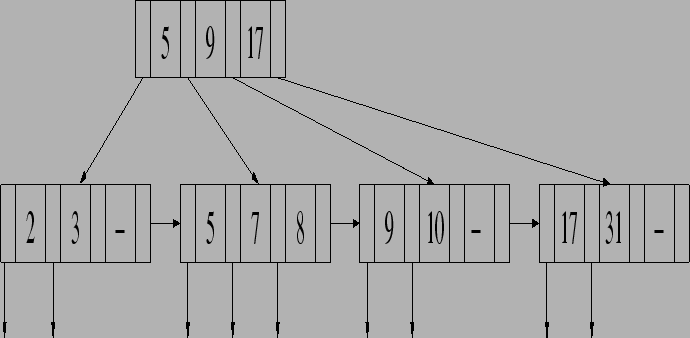
- Using simple iteration, for each tuple in R, we must perform an access for
every tuple in S. This requires
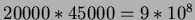 accesses.
Also need 20000 accesses to read R. Therefore, the total is 900,020,000 accesses.
accesses.
Also need 20000 accesses to read R. Therefore, the total is 900,020,000 accesses.
(Note: Must make R to be outer relation since it is smaller than S.)
- Block Iteration: Here, for each block in R, we must perform an access for
every block in S. The number of blocks of R is
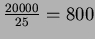 and number of blocks of S is
and number of blocks of S is
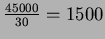 .
Therefore,
.
Therefore,
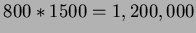 accesses are required.
In addition, 800 blocks of R have to be read. Therefore, total is
1,200,800.
accesses are required.
In addition, 800 blocks of R have to be read. Therefore, total is
1,200,800.
(Note: R must be made outer relation since it has fewer blocks than S.)
- Merge-Join:
Using merge-join, we assume the relations are already sorted by join attribute.
Therefore, we need to read each block of R and S only once. Therefore,
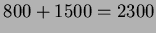 accesses only are required.
accesses only are required.
If the input relations are not already sorted on the join attribute, the cost of external merge-sort of the two relations should be added to the total cost.
Cost of external merge-sort =
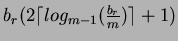
where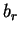 is the number of pages in the relation to be sorted and
is the number of pages in the relation to be sorted and 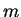 is the
number of memory pages available.
is the
number of memory pages available.
Cost of sorting relation R is
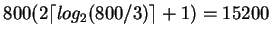
Cost of writing final sorted relation is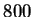 .
.
Cost of sorting relation S is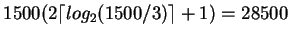
Cost of writing final sorted relation is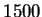 .
.
So total cost should be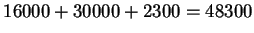 .
.
- Index Join:
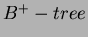 index exists on relation R and no index exists on relation S,
hence R will form the inner relation and S will form the outer relation.
The height of the index in worst case where the nodes are half-full is
index exists on relation R and no index exists on relation S,
hence R will form the inner relation and S will form the outer relation.
The height of the index in worst case where the nodes are half-full is
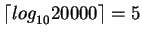 (case 1). The height of the index in
best case where the nodes are full is
(case 1). The height of the index in
best case where the nodes are full is
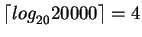 (case 2).
(case 2).
Assuming key-valued join attribute, for each block access from relation S, for each tuple in this block, the corresponding tuple in relation R will be accessed by descending the index and then accessing the data tuple.
Fetching relation S requires 1500 block accesses. Fetching the corresponding tuples from relation R would require 45000*(5+1) (case 1) or 45000*(4+1) (case 2) block accesses.
Thus, in all, the join would require 271500 (case 1) or 226500 (case 2) block accesses.
- Hash Join:
Here, we must first read in both relations in order to create the hash buckets. This requires reading of 800 + 1500 = 2300 accesses, and writing out of the hash buckets also costs 2300 accesses. Then reading the hash buckets pair-wise to compute the join costs another 2300 accesses. So, the total cost is 3 * 2300 = 6900 accesses.
If the hash buckets fit into memory, then the cost is only the initial read, which is 2300 accesses.
(Note that if only the join values and RIDs are maintained in the hash buckets, then the matching tuples have to be retrieved from disk. This can incur a cost of 20000+45000 = 65000 accesses since hashing results in random seeks.)
A better expression would be
![]()
This expression reduces COURSE (T) to only those values corresponding to credits of courses in CSA, which should be a small set. It also eliminates the unneeded attributes from COURSE (S). The cartesian product is therefore performed on the smallest amount of data possible.
- Yes, there is a relational algebra equivalent for LOJ :
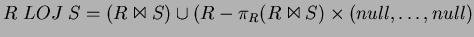
where the constant relation
 is on the schema
is on the schema 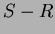 .
.
- The basic LOJ is not associative. For example, consider the following
schema:
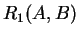 ;
; 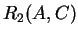 ;
; 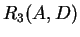 with contents
with contents 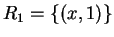 ,
,
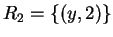 , and
, and 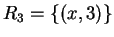 , then
, then
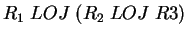 will output
will output
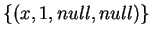 , while
, while
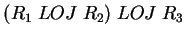 will give
will give
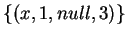 .
.
- No, LOJ is not commutative since
 itself is not a commutative operator.
itself is not a commutative operator.
- Since every tuple of
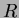 has to appear in the output, the minimum cardinality of
has to appear in the output, the minimum cardinality of
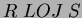 is
is  .
.
- With minor modifications all these algorithms can be used to compute LOJ.
| R | S | D | W | |
| R | Y | N | N | N |
| S | N | N | N | N |
| D | N | N | Y | Y |
| W | N | N | Y | Y |
The R and S locks are identical to the Read and Write locks discussed in class, and the various RS combinations are therefore obvious. Since the D and W locks alter the value of the balance, they conflict with the R and S locks. However, they don't conflict with themselves or with each other because they are commutative operations (order of deposits or withdrawals is immaterial).
|
|
: | R(a) | W(a) | R(d) | W(d) | ||||||||
|
|
: | R(d) | R(a) | W(a) | R(c) | ||||||||
|
|
: | R(b) | R(c) | W(c) | R(d) |
The schedule could not have been produced by 2PL because ![]() is allowed
to access item 'a' before
is allowed
to access item 'a' before ![]() which has already accessed item 'a' has
completed its growing phase.
which has already accessed item 'a' has
completed its growing phase.
The schedule could not have been produced by TO since ![]() 's write of data
item 'd' after
's write of data
item 'd' after ![]() has read it violates the pre-determined
serial order
has read it violates the pre-determined
serial order ![]() .
.
The schedule could have been produced by VT since the protocol is non-blocking.